

Разделение фронтенда и бекенда имеет множество преимуществ:
- Основная причина популярности API – это их универсальность, так как мы можем отправлять данные на любой тип клиента - для веба, мобильных устройств, настольных приложений и так далее.
- Разделение концепций. Давно ушли в прошлое те времена, когда мы имели одно монолитное приложение, где все компоненты были в куче. Представьте, что у вас есть по-настоящему запутанное приложение. Единственное, что вы можете в таком случае сделать – это нанять опытных разработчиков.
Понятное дело, что брать на работу новичков и учить их в рамках конкретной компании гораздо выгоднее, поэтому концепции все же стоит разделять. Таким образом мы можем уменьшить общую сложность приложения, делегируя ответственность на микро-сервисы, и уже каждая команда отвечает за свой микро-сервис.


Как было сказано ранее, начинающая команда работает гораздо лучше, если обязанности разбиты (бекенд, фронтенд, девопс и так далее).

Что мы будем делать
Здесь мы создадим мощное, гибкое NodeJS-приложение на базе GraphQL API с использованием Swagger-документации и на рельсах MongoDB.
Нашим скелетом послужит Hapi.js. Мы рассмотрим все этапы работы с технологией на детальном уровне.
В результате мы получим очень мощное GraphQL API с прекрасной документацией.
Вишенкой на торте станет интеграция с конечными клиентами (React, Vue, Angular).
Предварительные требования
- Установленный Node.js
- Базовые знания JavaScript
- Терминал (любой, лучше на основе bash)
- Текстовый редактор (любой)
- MongoDB (для Mac: brew install mongodb)
Начнем же!
Открываем терминал и создаем проект. Внутри директории проекта мы инициализировали новое Node.js-приложение.
Далее необходимо установить Hapi-сервер. Установим зависимости. Здесь мы можем использовать Yarn или NPM.


Но перед этим давайте поговорим, что такое Hapi.js и зачем он нам нужен.

Hapi.js позволяет писать удобные повторно используемые компоненты вместо продумывания определенной инфраструктуры.
Вместо работы с Express мы работаем с Hapi. Если кратко, то Hapi – это просто фреймворк Node.js. Причина выбора именно Hapi достаточно проста: простота и гибкость.
Благодаря этому мы создадим наш API в кратчайшие сроки.
Вторая зависимость, которую мы загрузим, это good-ole nodemon. При любых изменениях на стороне сервера Nodemon автоматически перезапускает сервер. Таким образом, скорость разработки увеличивается в разы.
Откроем проект через текстовый редактор. Я выбрал Visual Studio Code.
Настройка Hapi-сервера незамысловата. Создаем index.js в корневой директории и со следующим содержимым:
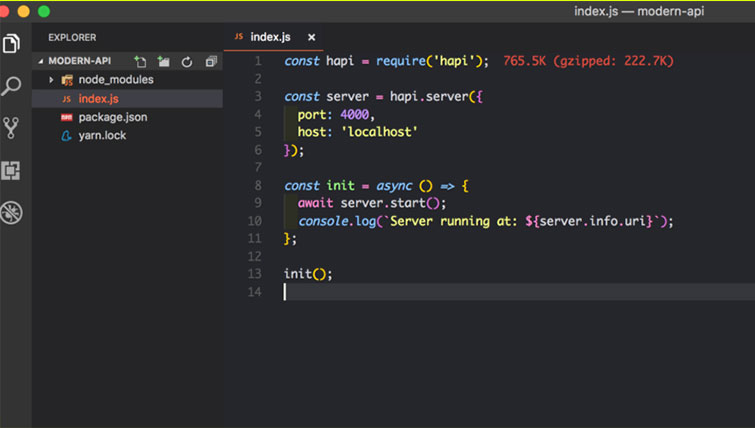
- Нам нужна Hapi-зависимость
- Во-вторых, мы создаем константу server, что создает новый экземпляр Hapi-сервера – в качестве аргументов мы передаем объект с данными о порте и настройками хоста.
- И наконец-то, мы создаем асинхронное выражение init. Внутри init мы объявляем другой асинхронный метод, запускающий сервер. Server.start() – и функция init().
Не уверены, что такое async – await? Смотрим это:
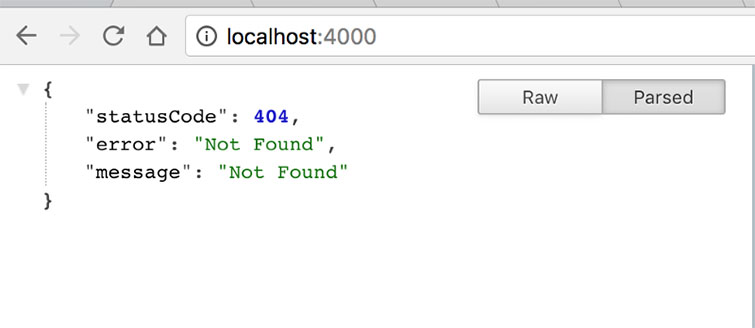
Так, если мы перейдем по указанному хосту, мы увидим следующее:
Что хорошо, так это то, что hapi требует маршрут и обработчик. Детальней об этом позже.
Теперь быстро добавляем скрипт для запуска сервера в связке с nodemon. Открываем package.json и редактируем секцию скриптов.

И двигаемся дальше.
Маршрутизация
Маршрутизация через Hapi интуитивно понятна. Мы вводим / и здесь мы можем указать три параметра:
- Путь – path
- Тип метода – get, post или что-либо еще? – method
- Обработчик маршрута – handler
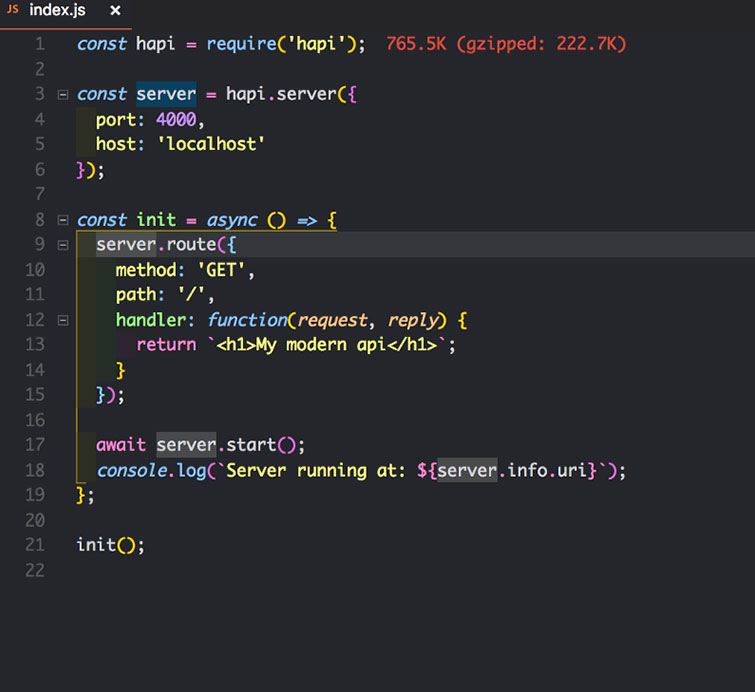
Внутри метода инициализации мы привязываем новый метод – route с параметрами в списке аргументов.
Если мы обновим страницу, мы увидим возвращаемое значение корневого обработчика.
Отлично, теперь двигаемся дальше!
Настройка базы данных
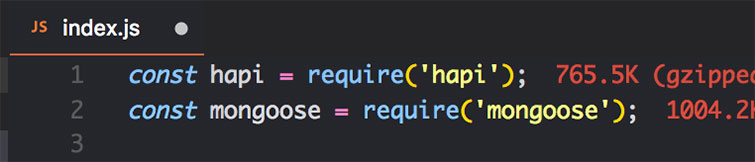
Теперь нам нужно установить базу данных. Здесь мы будем обходится mongodb в связке с mongoose.

Как по мне, создание MongoDB-валидации, приведение типов и так далее малость скучное занятие. Поэтому мы используем mongoose.
Відео курси за схожою тематикою:



Заключительный компонент базы данных – это mlab. Вместо запуска mongo на нашем локальном ПК мы используем облачный сервер.
Причина выбора именно mlab в его бесплатном тарифе (для прототипирования) и простоты использования. Вообще существует множество альтернатив, так что вы вольны выбирать.

Создаем базу данных и создаем пользователя для базы данных. На этом тут все.
Подключение mongoose с mlab
Откроем index.js и добавим следующие строки. Де-факто, мы просто говорим mongoose, к какой базе мы желаем подключиться. Указывать логин-пароль обязательно.

Если вы хотите освежить свои навыки MongoDB, вот отличная серия уроков.
Если же все прошло по плану, теперь мы должны увидеть в консоли “connected to database”.
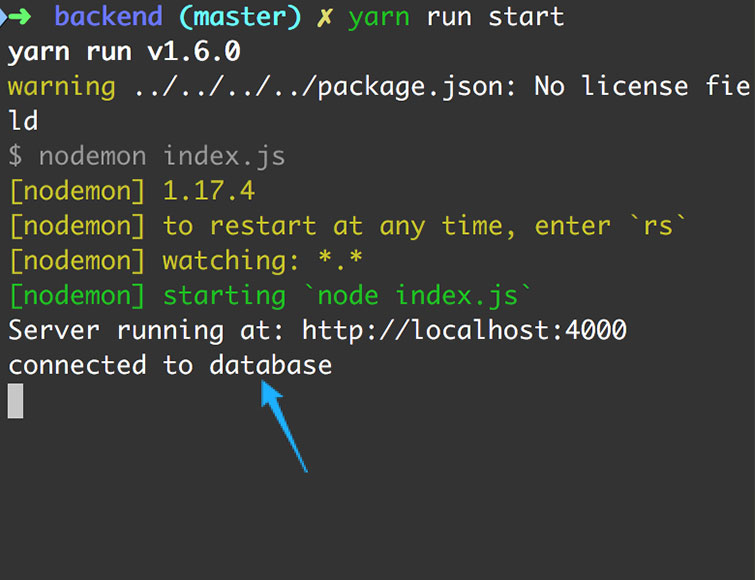
Ух!
Хорошая работа! Теперь пришло время для небольшого перерыва на кофе. Приступаем к разбору различных вкусностей.
Создание моделей
С MongoDB мы следуем определенным соглашениям моделей.

Относительно несложная концепция. По сути, мы просто объявляем нашу схему для коллекций. Под коллекциями понимайте таблицы в базе данных.
Создадим директорию под названием models. Внутри создадим файл Painting.js.
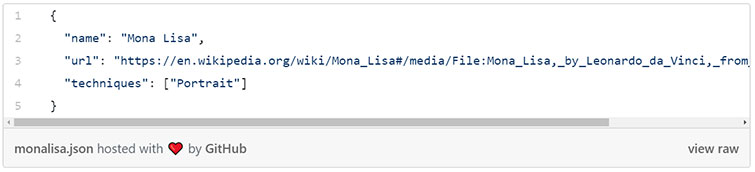
Painting.js будет представлять данные, связанные с картинами. Вот как она выглядит:
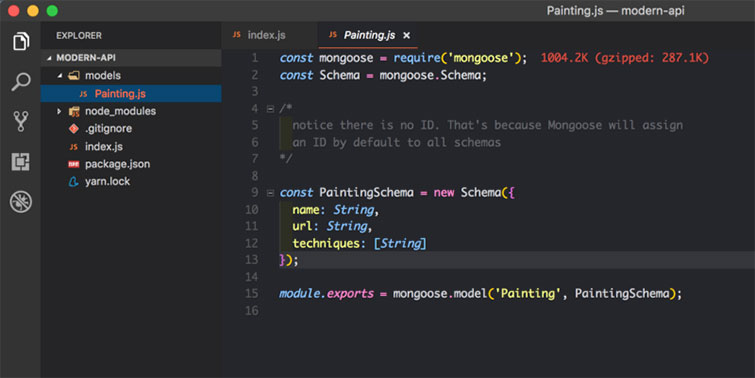
- Нам нужна зависимость mongoose
- Мы объявляем PaintingSchema при помощи вызова конструктора схем и передачи ему нужных параметров. Обратите внимание на строгую типизацию: name может содержать строку, а techniques – массив строк
- Экспортируем модели и называем их Painting
Получим все рисунки из базы данных

Для начала нам нужно импортировать модель Painting в index.js.
Прописывание маршрутов
В идеале название маршрутов должны отображать смысл их обработчиков.
Такие как /api/v1/paintings - /api/v1/paintings/{id} – и так далее.
Начнем с маршрутов GET, POST. GET получает все рисунки, а POST создает новые.
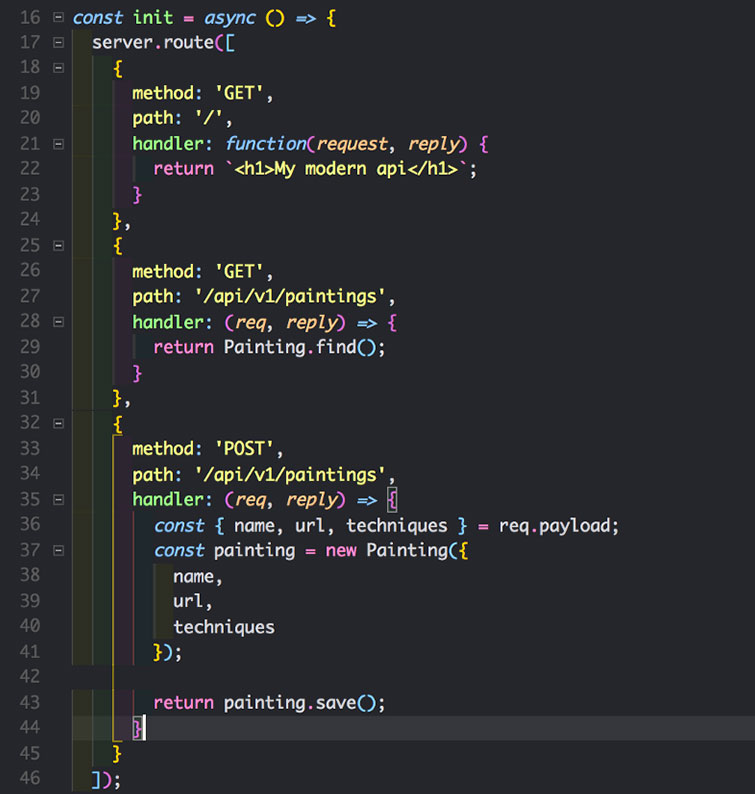
Обратите внимание, маршрут принимает массив объектов, а не один объект. Так же наши любимые стрелочные функции.
- Мы создали GET для /api/v1/paintings. Внутри обработчика мы вызываем схему mongoose. Mongoose имеет встроенные методы – весьма полезные, если мы используем find(), возвращающий все картины, так как мы не передаем в виде параметра ни единого условия.
- Так же для того же пути мы создали POST. Причина этому – следование соглашений REST. Давайте разберем обработчик запроса: помним, что схема Painting использует три поля – name – url – techniques. Здесь мы просто принимаем эти аргументы из запроса и передаем в схему. После передачи аргументов мы вызываем метод save() на новой записи и заносим его в mlab – базу данных.
Безкоштовні вебінари за схожою тематикою:



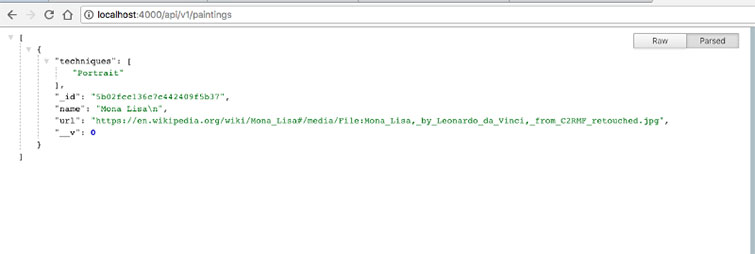
Если мы перейдем по указанному адресу, мы увидим пустой массив.
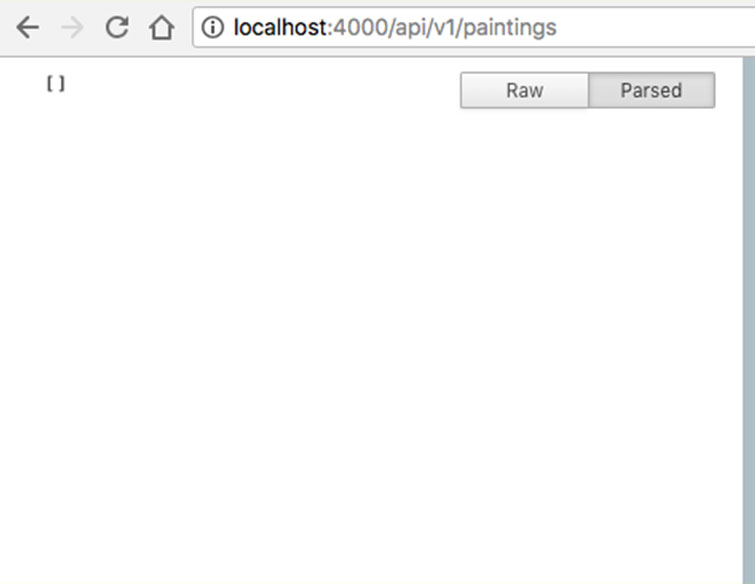
Почему пустой? Да потому что мы еще ничего не добавили!

Установите postman, он доступен на всех платформах.
После установки откроем его.
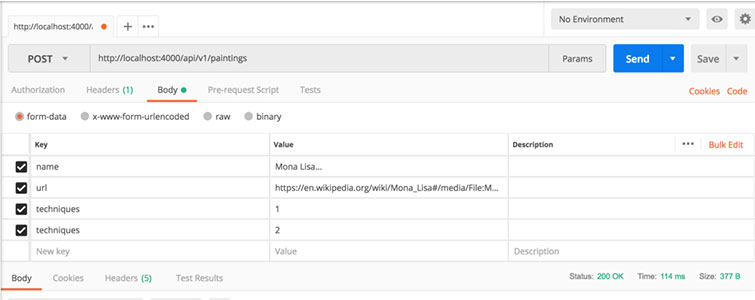
- Слева мы видим опции методов. Меняем на POST.
- Далее URL. Адрес, по которому мы оправляем запрос.
- Справа синяя клавиша отправки запроса.
- Ниже url следующие опции. Кликаем на тело и заполняем поля, как в примере.
Отлично. Теперь пробуем еще раз!
Отлично! Но у нас все еще есть, с чем разобраться. GraphQL!
Если кому нужно, вот исходный код.
На этом пока что все, до новых встреч!
Автор перевода: Евгений Лукашук
Статті за схожою тематикою





