

Обобщенный паттерн Репозиторий
Чтобы избежать недоразумений, давайте для начала проясним, что здесь имеется ввиду под понятием обобщенного репозитория. Видели ли вы когда-нибудь интерфейс вроде этого:

Или может вы видели его брата-близнеца, который имеет иной вариант метода Get:

Вдохновение для написания первого примера пришло из официальной документации Microsoft для ASP.NET MVC 4. Что же касательно второго примера, в Интернете вы можете найти бесконечное число блогов, описывающих именно этот вариант написания репозитория — иногда лишь с небольшими отличиями в виде возвращения IEnumerable<TEntity> вместо IQueryable<TEntity>. И в последнем случае часто еще и с дополнительным методом для генерации запросов. Что-то вроде этого:

Так что плохого в них, вы можете спросить? Почти ничего, если не считать плохое именование методов из примера Microsoft (здесь лучше было бы использовать Find и FindAll вместо Get и GetAll).
Но «почти ничего» - это далеко не то же самое, что «ничего». Первую проблему, которую я здесь вижу, так это нарушение Принципа Сегрегации Интерфейсов (Interface Segregation Principle). Они выражают полный набор CRUD-операций даже для тех сущностей, для которых операции удаления не имеют никакого смысла (к примеру, когда вы деактивируете пользователей вместо удаления их записей из базы данных). Но эта проблема может быть решена при помощи просто разбиения на три интерфейса — для чтения, обновления и удаления записей.


Реальная проблема, которую мы здесь имеем, заключается в некорректном использовании. Оригинальная идея заключается в том, что интерфейсы должны быть использованы в качестве базовых для ваших пользовательских интерфейсов. Что-то вроде этого:

Ваши обработчики событий и сервисы (клиенты пользовательских репозиториев) должны сами определять нужные методы и помещать их в пользовательские интерфейсы.
Это в теории. К сожалению, за свою карьеру мне довольно часто приходилось видеть несколько иную картину:

Кто-то создал рабочую реализацию IGenericRepository. Что хуже в этой реализации, так это то, что эта имплементация почти всегда регистрируется в IoC-контейнере и может быть внедрена в ваши обработчики команд и сервисы точно так же, как и любая другая зависимость.

Код выглядит достаточно красиво и чисто. На самом деле — нет. Почему именно так — скажу немного позже. Теперь же я бы хотел поговорить об одном из решений неправильной интерпретации GenericRepository<T> многих разработчиков. Само решение выглядит примерно так (диалог на code-review):
Джим Сеньор: вы когда-либо слышали, что NHibernate ISession или DbSet из Entity Framework на самом деле репозитории? А то, что вы только что создали — всего лишь небольшая обертка над ISession или DbSet? Де-факто, мы можем отказаться от этого обобщенного репозитория и просто использовать DbSet — результат будет аналогичным. Единственное, в чем IGenericRepository<T> действительно полезен — так это в том, что он скрывает большую часть ненужных для нас методов, которыми обладает DbSet.
Джонни Джуниор: да, в этом действительно есть смысл. Я полагаю, использование обобщенного репозитория в нашем случае было лишним (счастливо возвращаемся к написанию программы…)
Как по мне, что GenericRepository<T>, что DbSet – в большинстве ситуаций их использование лишнее (ну разве что вы пишите наиболее заCRUDженное приложение в своей жизни). Почему? Вот почему:
- Единственный способ убедиться, что все LINQ-запросы будут верно преобразованы в SQL — это протестировать их на том же типе базы данных, что находятся в продакшине. Кроме того, в таком случае задача написания интеграционных тестов становится достаточно затруднительной. К примеру, взглянем на код:
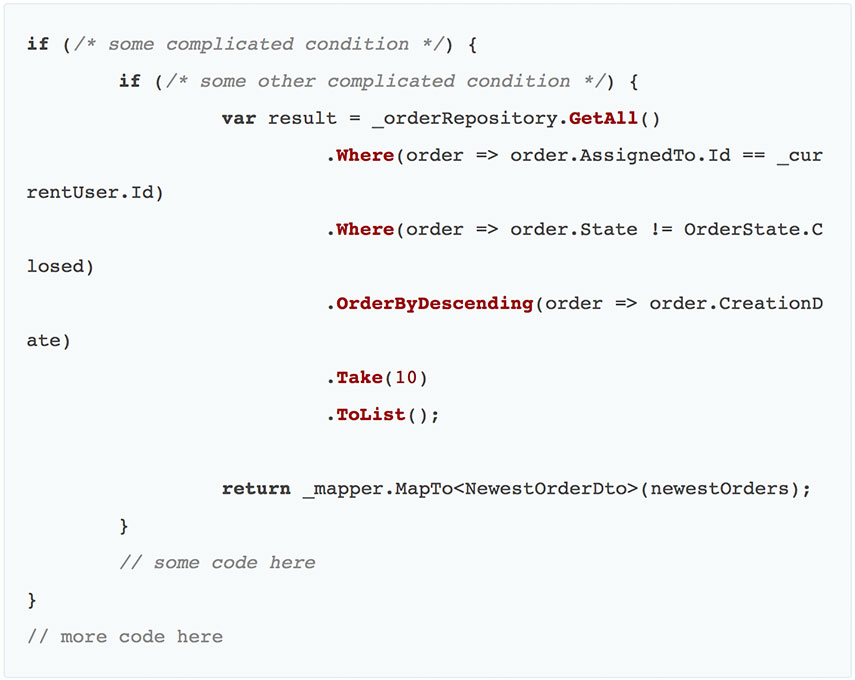
Чтобы выполнить эти запросы, должны быть соблюдены два условия. За счет этого интеграционный тест становится менее читабельным. Теперь же давайте представим, что этот метод помещен в метод репозитория. Теперь в тесте нам нужно просто вызвать метод репозитория и проверить результат — просто, не так ли?
- Я уверен, вы согласитесь, что LINQ-предикаты внутри сервисов нельзя использовать повторно и они имеют плохую тенденцию повторяться на протяжении всего кода. Даже если программист желает извлечь запрос в свой собственный метод, обычно это будет приватный метод конкретного сервиса. Инкапсуляция запросов внутри методов репозитория приведет к большей читабельности кода и в значительной мере упростить его использование.
- LINQ-предикаты не именуются. Как правило, единственный способ узнать, что же, собственно говоря, делает наш запрос (без углубления в его логику), так это имя переменной-результата. К сожалению, искусство информативного именования переменных постигается с опытом, а поскольку в нашей индустрии полно начинающих программистов, мы имеем дело с переменными вроде result, ordersToProcess или просто — orders. Создавая обертку над запросами в виде метода репозитория, это автоматически обязывает разработчика дать этому самому методу конкретное имя. Даже если это имя не из лучших, в последствии провести небольшой рефакторинг не составит труда!
- Порой, по причине скорости, мы вынуждены доставать данные из базы посредством чистого SQL. Подумайте, вы действительно хотите в своей бизнес-логике работать с такими низкоуровневыми сущностями, как DbConnection или SqlException? Подобный код лучше прятать за методами репозиториями.
Никаких обобщений — только конкретные репозитории
Перед тем как начать разработку репозитория, необходимо определить его интерфейс. Интерфейс должен содержать только те методы, которые нужны конечным клиентам. Другими словами, если никому не нужно удалять сущности данного типа, нет никакого смысла в написании функционала для их удаления.
Если вы боитесь закончить среди разных имен для базовых CRUD-операций — таких как Delete в одном репозитории и Remove в другом — вы можете создать полезные интерфейсы типа ICanDeleteEntity<TEntity>, ICanUpdateEntity<TEntity> и так далее. В таком случае конкретный репозиторий будет реализовывать только действительно нужные из них.
Видео курсы по схожей тематике:



Ни один из методов репозитория не должен возвращать IQueryable<T>. Также убедитесь, что репозиторий не возвращает IQueryable<T>, скрытые за IEnumerable<T>. Всегда вызывайте ToList() или ToArray() дабы «материализовать» значения, придав им более конкретный тип данных.
Как только заходит речь о реализации репозитория, вы можете наследовать абстрактный класс GenericRepository<TEntity>. Если угодно — можно также использовать напрямую ISession и DbSet. Не важно, какой подход вы выбираете. Помните: любые «лишние» в данном контексте методы — по типу Delete из базового класса — будут скрыты за интерфейсом репозитория.
Также не забывайте, что ваш репозиторий не несет ответственности за транзакции базы данных. Лучше всего эта концепция реализуется при помощи паттерна Unit Of Work. Этот паттерн уже реализован в рамках ISession и DatabaseContext. Все, что нам нужно — это хороший интерфейс над ними:

Для большинства веб-приложений чтобы начать транзакцию через IUnitOfWork в виде начала запроса и Commit / Rollback в конце запроса — этого функционала вполне достаточно. Так же подобное может быть достигнуто при помощи фильтров действий или декораторов обработчиков / сервисов.
Пример репозитория, созданного при соблюдении всех приведенных рекомендаций:
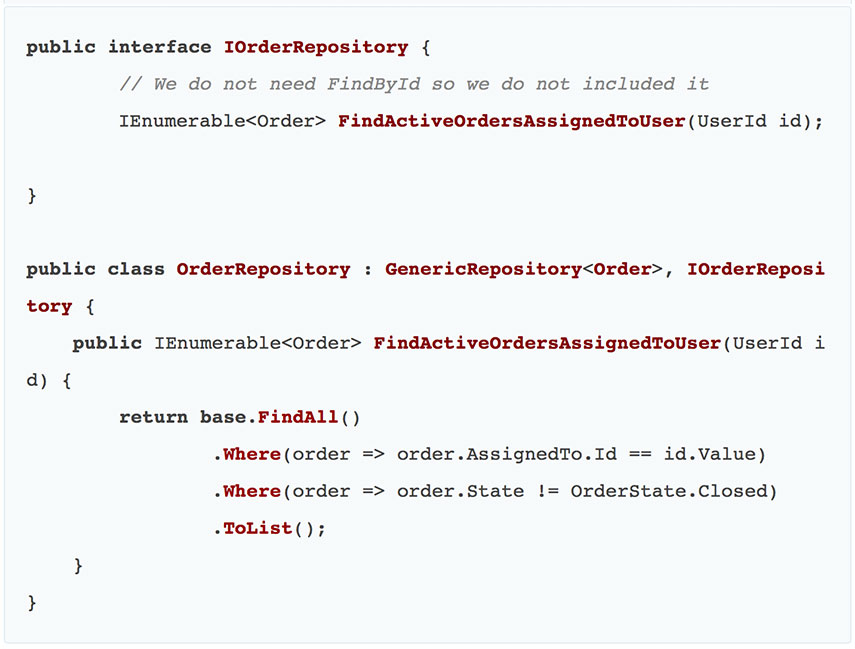
Сейчас все стало ясно, но давайте еще раз проясним. Каждый метод наших репозиториев должен быть учтен по крайней мере одним интеграционным тестом, который должен использовать тот же тип базы данных, что и продакшн. Всегда используйте интеграционные тесты для проверки своих репозиториев.
Немного о недостатках
Не существует роз без шипов, и представленный выше подход — не исключение. Некоторые из них можно решить, используя отличимую от трехуровневой архитектуру. Наиболее часто с конкретными репозиториями возникали следующие проблемы:
- За длительное время репозитории могут набрать большое количество Find-методов. Достаточно часто эти методы похожи друг на друга. Есть два способа это предотвратить. Один из них — это группировка нескольких Find-методов в один общий. Этот метод должен принимать object, что представляет собой критерий запроса. Пример:

Чтобы создать запрос с критерием запроса, мы строим набор критериев шаг за шагом:

Зачастую слишком большие репозитории обрастают целой плеядой различных сервисов. Вы можете избежать этого при помощи чего-то, что я называю CQRS-light. Отличием от полной версии является использование тех же таблиц как для чтения, так и для записи. Используя эту технологию, мы можем использовать ту же самую ORM как для чтения, так и для записи. Обращаться же к CQRS только в тех случаях, когда приложение в этом действительно нуждается (например, при обработке 80+ колонок, с использованием 20+ join). Диаграмма ниже представляет типичную архитектуру CQRS-приложения:
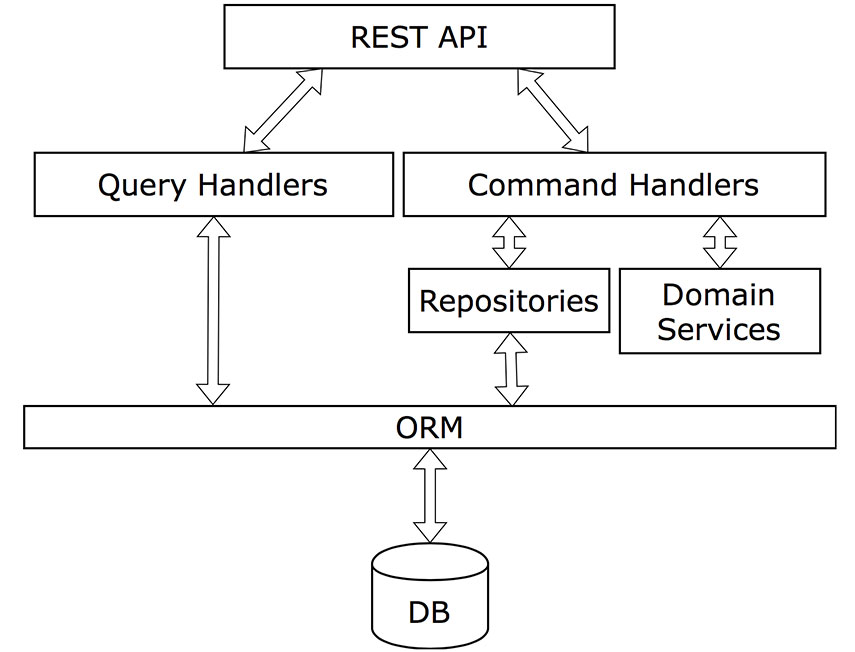
Ключевые принципы CQRS-light следующие:
- Деление всех действий пользователя на две категории. Первая категория — действия, изменяющие систему. К примеру, оформление заказа в интернет-магазине. Вторая категория — действия, систему не трогающие. К примеру, просмотр списка товаров. Первая категория пишет — это команды, другая — читает, это запросы.
- Обработчики запросов для доступа к данным могут использовать только репозитории. Доступ к данным может осуществяться посредством любой технологии. Обычная конфигурация включает в себя ORM для чтения-записи, ORM для записи и микро-ORM для чтения (вроде Dapper) или же ORM для записи и чистый SQL для чтения.
- Обработчики команд для доступа и изменения данных могут использовать только репозитории. Для получения данных из базы обработчики команд не должны использовать обработчики запросов. Если обработчик команд должен выполнить комплексный запрос и этот запрос должен получить ответ от обработчика запроса, вы должны продублировать логику этого обработчика запроса и поместить его как в обработчик запроса, так и в метод репозитория (операции чтения и записи должны быть разделены).
- Обработчики запросов тестируются только в интеграционных тестах. Для обработчиков команд существуют юнит и — опционально — также интеграционные тесты.
Бесплатные вебинары по схожей тематике:



CQRS даже в своей легкой форме — сама по себе объемная тема и заслуживает отдельного блога.
Теперь же давайте вернемся к теме недостатков паттерна конкретного репозитория. Другой недостаток, о котором я бы хотел упомянуть, заключается в нежелательной миграции бизнес-логики в определение запросов. К примеру, даже такой простой запрос:

содержит часть бизнес-логики, описывающей необходимые параметры, дабы заказ стал активным. Как правило, ORM не позволяет нам инкапсулировать такие части логики в отдельные свойства, как IsActive.
Что нам здесь нужно, так это паттерн спецификации. Теперь наш запрос в форме паттерна спецификации будет выглядеть так:
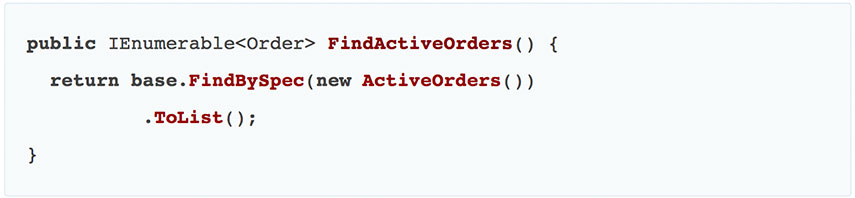
Автор перевода: Евгений Лукашук
Статьи по схожей тематике






