

Введение
В данной статье речь пойдет о такой части теории проектирования реляционных баз данных, как нормализация. Но для начала уделим немного внимания основным понятиям и самой сути реляционной теории, и вот почему:
в представлении многих термин «реляционная» в контексте баз данных означает то их свойство, что таблицы существуют не сами по себе, а связаны (от англ. «relation» – связь, соотношение) между собой (с помощью ключей).
На самом деле это не так, данный термин происходит от математического термина «relation» (отношение) и означает представление множества́ в теории множеств. В реляционной модели отношение – это множество связанных между собой данных, которые в базе данных реализуются в виде таблицы.
Мы отождествляем понятия отношения и таблицы, кортежи называем строками, атрибуты – столбцами. Кристофер Дейт (один из ведущих специалистов в области реляционной модели данных) называет эти понятия «дружественными», но отнюдь не равными и приводит пример с картиной художника Рене Магритта «Вероломство образов».


 Надпись на картине гласит – «Это не трубка». И действительно, картина с изображением трубки – это не сама трубка, а её образ.
Надпись на картине гласит – «Это не трубка». И действительно, картина с изображением трубки – это не сама трубка, а её образ.
Точно так же таблица SQL – это не отношение, а лишь удачное изображение отношения. SQL (с null типами, которым не место в теории множеств и пр.) – это не реляционная модель в чистом виде, а лишь ее реализация. Поэтому из всех определений термина «нормализация» более всего мне нравится следующее – это использование SQL в реляционном духе.
В классической теории множеств по определению любое множество состоит из различных элементов. Отношение состоит из множества кортежей (кортеж (строка) – множество пар «атрибут : значение»; атрибут (поле, столбец) – свойство некой сущности; домен – множество допустимых значений атрибута). Таким образом, в отношении нет одинаковых кортежей, порядок следования кортежей и атрибутов не определен. Из этого следует, что отношения (не таблицы) всегда нормализованы (точнее, находятся в первой нормальной форме).
Первая нормальная форма (1НФ)
Каждый кортеж отношения содержит единственное значение соответствующего типа (домена) в позиции любого атрибута. Или, проще говоря, в табличном представлении отношения на пересечении любой строки и любого столбца мы видим только одно значение.
 Допустим, у нас есть предприятие по доставке пиццы. Мы собрали все факты о заказах и у нас получилась следующая таблица:
Допустим, у нас есть предприятие по доставке пиццы. Мы собрали все факты о заказах и у нас получилась следующая таблица:

Атрибут Order содержит несколько повторяющихся значений, наверняка, домен данного атрибута должен состоять из множества товаров из меню пиццерии (но никак не из множества списков товаров), а количество товара в заказе вообще относится к другому атрибуту. Также, в информации о заказчике (CustomerData) следовало бы выделить в отдельный атрибут номер телефона, причем у мистера Cheng Tsui их два.
После данных замечаний мы бы могли переделать таблицу под следующий вид:

Конечно же, следовало бы еще разделить наши Product1, Product2, Product3 на товар (beer, pizza и т.д.) и название товара (Papperoni , Veggie, SA и т.д.), а объем бутылки (0,5), который я вообще удалил, тоже определить в отдельный атрибут. Но основная проблема в этой таблице – это наличие переменного количества столбцов под продукт. И если с телефонами это не так критично (мы не будет хранить более двух номеров одного клиента), то с продуктами в одном заказе дела обстоят иначе. Конечно же, такие повторяющиеся атрибуты (отличаются только названием, но не доменом) не вписываются и в реляционную модель; от повторения кортежей (строк) нас избавит наличие атрибута OrderNo (ведь один клиент в один день может сделать идентичный заказ и ему его доставит, допустим, тот же курьер), который выступает явным претендентом на первичный ключ.
В общем, возвращаемся к тому, что таблицу нужно изменить, да и вообще, наверное, пора задуматься о том, что было бы неплохо ее разбить на несколько таблиц. Но пока что мы её модифицируем в следующий вид:

Здесь мы ввели дополнительный атрибут OrderItem, и теперь наш атрибут OrderNo не может уникально идентифицировать строку, похоже, наш первичный ключ будет составным (OrderNo, OrderItem). Пора бы перейти ко второй нормальной форме.
Стоп! А как же атомарность значений?
Атомарные данные – это данные, разделенные на наименьшие значения, дальнейшее деление которых невозможно или нецелесообразно. Например, атрибут Customer можно разбить на Фамилию и Имя, из Customer Address выделить улицу, дом, квартиру и так далее.
Видео курсы по схожей тематике:



По этому поводу среди специалистов существует спор, стоит ли данное понятие включать в нормализацию и вообще уделять ему внимание. Конечно же, атомарность упрощает контроль над правильностью данных в таблице (определение более четкого домена, например, номерами домов должны быть только целые положительные числа), но, с другой стороны, это не должно быть панацеей. Допустим, наша пиццерия находится в небольшом городе, мы не планируем собирать статистику заказов по улицам (например, для принятия решения об открытии нового отделения на улице с наибольшим количеством продаж), а единственным пользователем данной информации (поле Customer Address) будет курьер и ему вполне приемлемо видеть адрес целиком. При необходимости, мы всегда сможем написать и такое выражение для выборки:
SELECT * FROM Orders
WHERE [Customer Address] LIKE '%Shevchenko%'
Вторая нормальная форма (2НФ)
Если у Вас несоставной первичный ключ, переходите к третьей нормальной форме.
Вторая нормальная форма начинает избавлять нас от избыточности данных (дублирования) в той части, что в таблице не должно быть неключевых столбцов, которые функционально не зависят от всего первичного ключа.
В нашем случае целый ряд атрибутов не зависит от части ключа – столбца OrderItem: Date, Customer, Customer Address, телефоны, Courier. Пора таблицу разбить на несколько (Customers, OrderInfo, Orders):
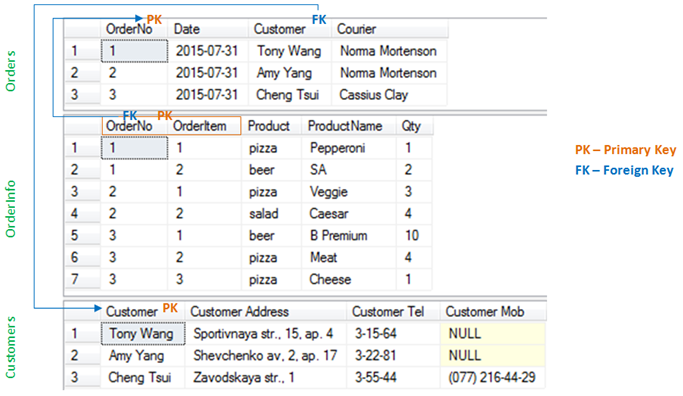
Третья нормальная форма (3НФ)
Мы уже пришли к первой и второй нормальным формам и пора задуматься о третьей, которая связана с транзитивными зависимостями. Данная зависимость возникает тогда, когда неключевой атрибут зависит от первичного ключа не напрямую, непосредственно, а транзитивно, т.е. через другой неключевой атрибут. Такого быть не должно. Наверняка, в базе данных нашей пиццерии есть таблица о сотрудниках: уже знакомые нам курьеры, а также телефонные операторы, повара, директор и другие. Пусть данная таблица содержит информацию о должностях и окладах:
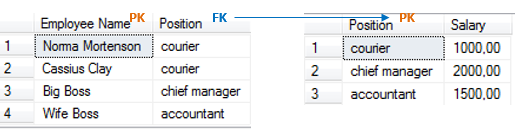
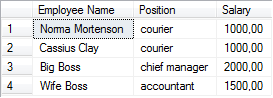 Первичный ключ – на поле Employee Name. Поле Salary зависит от поля Employee Name (PK) транзитивно (через поле Position). Проще говоря, оклад зависит от должности (напрямую), а не от имени (конечно же, при условии, что по существующей бизнес-логике оклад действительно определен на каждую должность, а не на отдельного сотрудника, т.е. не может быть двух курьеров с разными окладами). Следует разделить таблицы.
Первичный ключ – на поле Employee Name. Поле Salary зависит от поля Employee Name (PK) транзитивно (через поле Position). Проще говоря, оклад зависит от должности (напрямую), а не от имени (конечно же, при условии, что по существующей бизнес-логике оклад действительно определен на каждую должность, а не на отдельного сотрудника, т.е. не может быть двух курьеров с разными окладами). Следует разделить таблицы.
Нормальная форма Бойса-Кодда (BCNF)
Данная нормальная форма расширяет 3НФ, естественно, подразумевает предварительное приведение к 3НФ и не должно быть других потенциальных первичных ключей, иными словами – не должно быть зависимости атрибутов первичного ключа от других неключевых атрибутов.
Давайте вернемся к таблице OrderInfo. У нас есть составной первичный ключ по полям OrderNo, OrderItem, но мы могли бы сделать ключ и по полям OrderNo, ProductName. Нужно вынести информацию о продукте (поля Product, ProductName) в отдельную таблицу, добавить поле ProductId, которое будет ссылаться (FK) на таблицу с информацией о продуктах.
Бесплатные вебинары по схожей тематике:



Существует еще 4НФ, 5НФ и даже 6НФ, но они почти не имеют практического применения и в данной статье рассматриваться не будут.
Пора сделать некие выводы и поговорить о значимости нормализации. Во-первых, мы избавляемся от избыточности данных, а значит – экономим память. Во-вторых, мы решаем проблемы обновления данных, исключаем связанные с этим возможные возникновения аномалий. В-третьих, упрощаем контроль целостности данных. В-четвертых, база данных более понятно описывает реальный мир и готова к дальнейшему расширению.
Статьи по схожей тематике





